Anthropic’s Claude 4 series is a game-changer for developers, researchers, and AI fans alike in the fast-changing world of artificial intelligence. The powerful Claude Opus 4.1 and the streamlined Claude Sonnet 4 are both part of this new lineup that came out in May 2025. Both were designed to be great at AI-assisted coding, advanced reasoning, and complex agentic workflows. Let’s say you’re trying to decide between Claude Opus 4.1 vs Sonnet 4 or find the best AI model for coding in 2025.
In that case, this comprehensive comparison will guide you through their key features, benchmark performances, real-world applications, and head-to-head matchups. We’ll also explore how they fare against rivals like OpenAI’s GPT-5 and Google’s Gemini, drawing from official Anthropic data, independent benchmarks, and community insights from platforms like Reddit and X.
Table of Contents
As an AI expert tracking the latest advancements—from OpenAI’s GPT evolutions to Google’s Gemini updates—I’ve witnessed countless breakthroughs. But Claude 4’s focus on safe, understandable AI seems like a real change in the way things are done, especially when it comes to doing complicated, multi-step tasks with accuracy.
This guide is based on Anthropic’s releases, reviews from other people, and conversations with users. Its goal is to help you pick the right model for your needs, whether you want to build autonomous agents or solve difficult software engineering problems.

The Evolution of Claude 4: History, Release Timeline, and Key Innovations
Anthropic was started by former leaders of OpenAI and focuses on AI safety. The company is known for making “helpful, harmless, and honest” models using constitutional AI frameworks. The Claude 3 series, which includes Opus, Sonnet, and Haiku, was the best in 2024.Anthropic was started by former leaders of OpenAI and focuses on AI safety.
The company is known for making “helpful, harmless, and honest” models using constitutional AI frameworks. The Claude 3 series, which includes Opus, Sonnet, and Haiku, was the best in 2024. However, by early 2025, the growing need for enhanced agentic AI—capable of planning, executing, and iterating like human experts—spurred the development of Claude 4.
During Anthropic’s “Code with Claude” keynote on May 22, 2025, Claude 4 introduced Opus 4 as the best coding AI and Sonnet 4 as a flexible upgrade from Sonnet 3.7, with better coding accuracy, deeper reasoning, and more efficient operations. On August 5, 2025, Anthropic released Claude Opus 4.1, delivering a “one standard deviation” improvement over Opus 4 in junior developer benchmarks—equivalent to the leap from Sonnet 3.7 to Sonnet 4.
These models employ hybrid architectures, seamlessly switching between rapid responses for simple queries and prolonged “extended thinking” for in-depth analysis. They include tools like web searches to improve accuracy and can handle large context windows. Opus 4.1 costs a lot of money (about $75 per million output tokens), but Sonnet 4 is more affordable. The choice comes down to balancing power with usefulness.
Claude Sonnet 4: The Balanced Performer for Everyday AI Tasks
Claude Sonnet 4 is the best choice for developers who want a balance of intelligence, speed, and low cost. As a member of the Claude 4 family, it’s made for situations where a lot of data needs to be processed quickly, like scaling AI in business apps or regular software development. According to early tests, it cuts down on errors by 25% and speeds up response times by 40% compared to Sonnet 3.7.
Key highlights include:
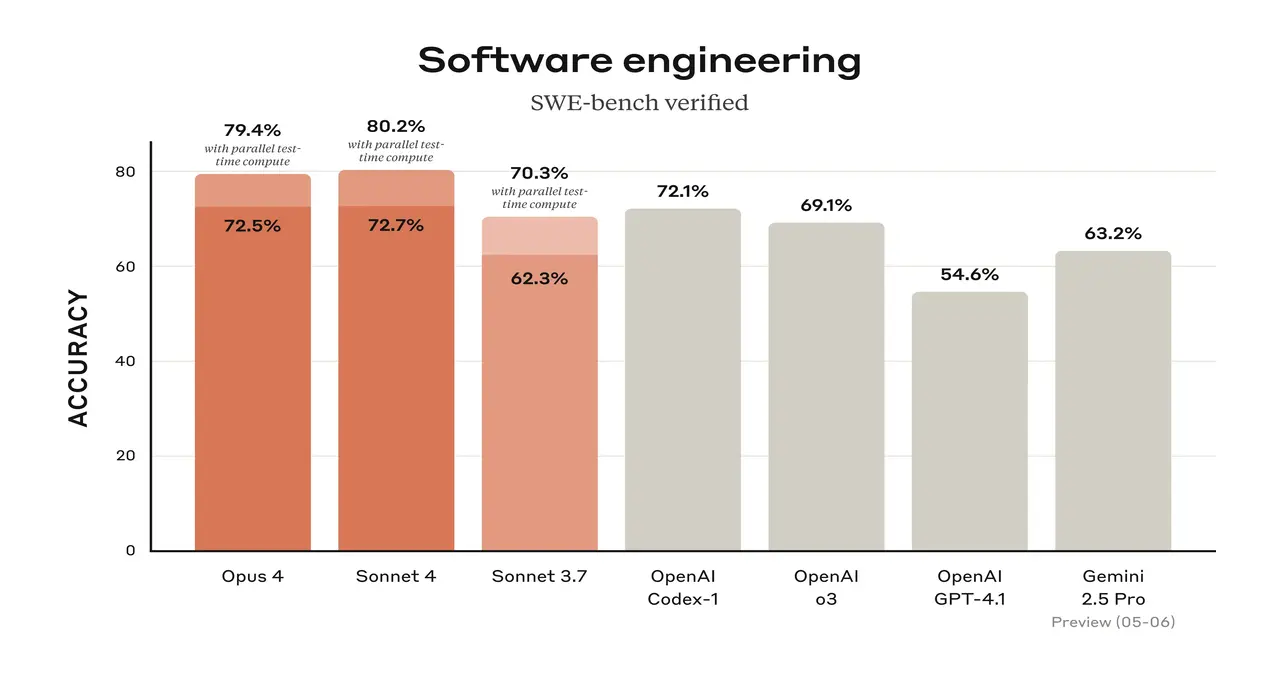
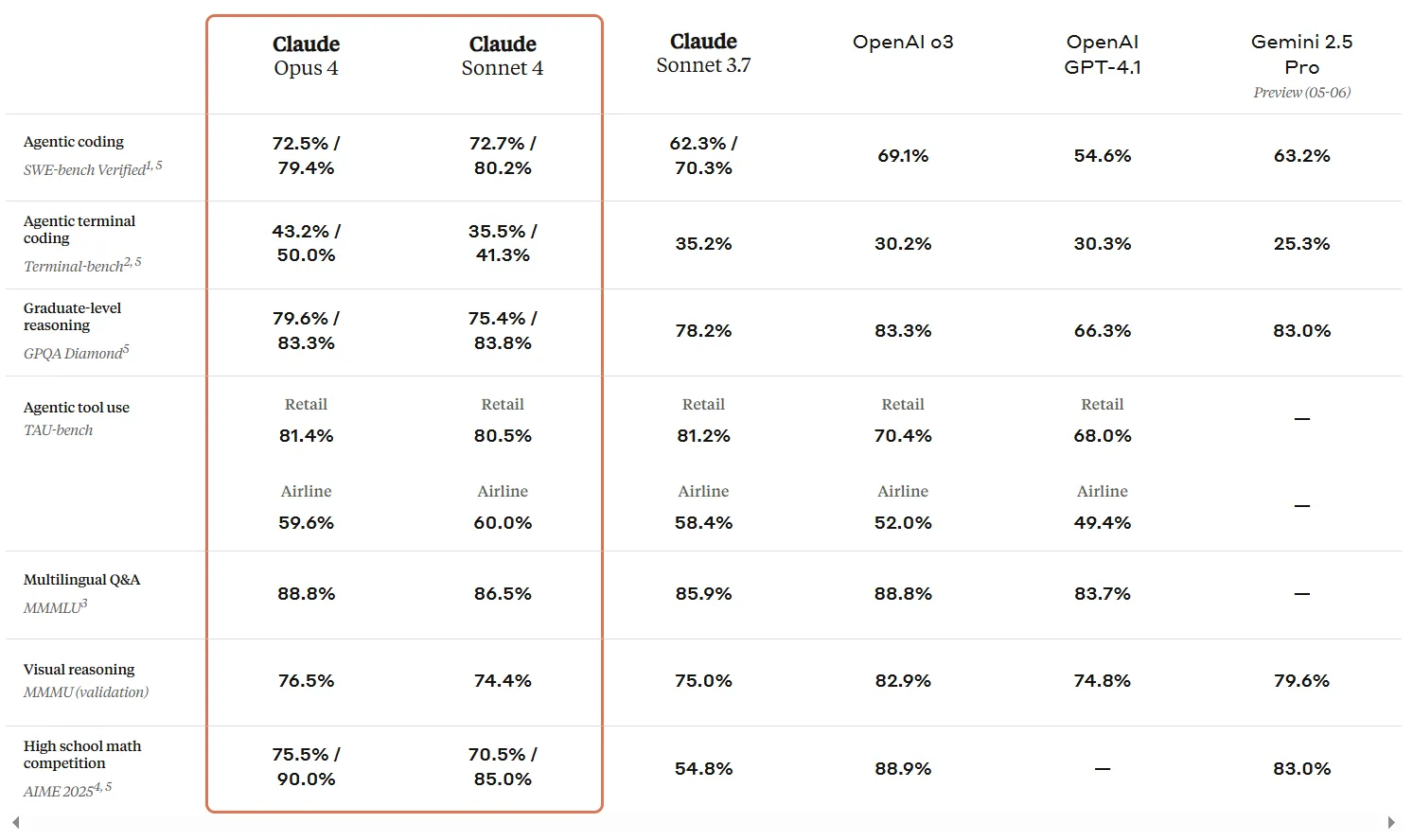
- Advanced Coding and Reasoning: Gets 72.7% on the SWE-bench (Software Engineering Benchmark), just beating Opus 4’s 72.5%. It cuts down on “reward hacking” by as much as eight times, making sure that outputs are ethical and reliable.
- Scalable Efficiency: Features a 200K token context window, optimized for swift code reviews, debugging, and feature implementations. Users laud its practicality for most AI scenarios, delivering elite performance at a lower cost.
- Agentic Excellence: Scores 80.5% on TAU-bench for multi-step workflows, ideal for retail automation or enterprise tools.
People who use Reddit say that Sonnet 4 is reliable. For example, a quantitative finance expert praised its detail-oriented approach to financial modeling, and an app developer said it was better at fixing mistakes. What are the downsides? It might not work as well on very complex architectures. It’s great for everyday use because it costs less and has 54.84 tokens per second.
Claude Opus 4.1: The Elite Model for Complex Challenges
Claude Opus 4.1 is the best of the best for people who want the best intelligence. People say that Anthropic’s Opus 4, which was released on August 5, 2025, is the best thing they’ve ever made. It does great in long coding marathons and independent research. It stays fast even after long periods of use, making it great for refactoring large codebases or simulating systems with multiple layers.
Standout attributes:
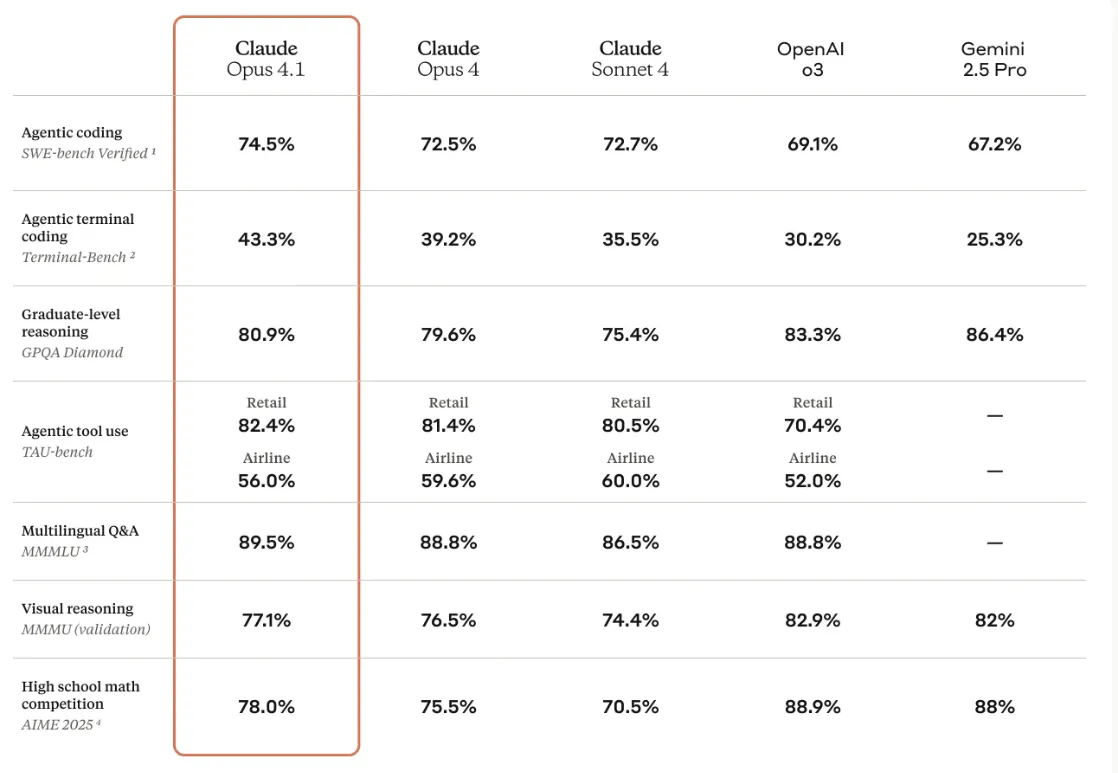
- Superior Intelligence: It has the highest score on SWE-bench (74.5%), as well as 90% in high school math, 88.8% in multilingual Q&A, and 76.5% in visual reasoning.
- Robust Agentic Features: Handles enterprise-level tasks with ease and supports 32K tokens for huge projects. It also does well on agent benchmarks.
- Hybrid Reasoning Modes: Enhances extended thinking by up to 50% in terminal coding accuracy (50% success rate), toggling modes for optimal results.
User sentiments on X and Reddit are mixed: Anthropic’s announcements emphasize its dominance, but some report minor inconsistencies or overcomplexity. A firmware engineer preferred Sonnet for simplicity, yet Opus excels in layered, PhD-level problems. Even though it costs more and is a little slower (1.82 seconds to first token), it’s necessary for cutting-edge work.
Head-to-Head Comparison: Claude Opus 4.1 vs Sonnet 4
To make the battle clearer, here’s a detailed table that compares specs, benchmarks, and best uses. It comes from Anthropic documentation and reviews from other sources.
| Aspect | Claude Sonnet 4 | Claude Opus 4.1 |
|---|---|---|
| Release Date | May 22, 2025 | August 5, 2025 (upgrade from Opus 4) |
| Strengths | Efficiency, general tasks, software engineering | Complex reasoning, agentic workflows, advanced coding |
| SWE-bench Score | 72.7% | 74.5% |
| TAU-bench (Retail) | 80.5% | 81.4% |
| Math (High School) | 85% | 90% |
| Speed (Tokens/sec) | 54.84 | ~40 (slower for deeper processing) |
| Cost (per M Output Tokens) | ~$15 | ~$75 |
| Best For | Daily development, high-volume work | Long-horizon tasks, enterprise AI |
Sonnet 4 edges out in value, while Opus 4.1 leads in capability.
Real-World Applications and Community Feedback
Sonnet 4 thrives in startup environments and app development, with X users reporting reduced failure rates in production (from 10% to 6%). Opus 4.1 suits research and large enterprises, mastering multi-layer data flows.
Insights from X:
Reddit’s r/ClaudeAI forums favor Sonnet for UX design and Opus for intricate issues.
Final Verdict: Choosing Between Opus 4.1 and Sonnet 4
Ultimately, the winner depends on your priorities. Opt for Sonnet 4 for speedy, cost-effective performance in standard tasks. If you want to work on big, hard projects, choose Opus 4.1. Both move Anthropic’s vision of trustworthy AI forward, turning into important partners.
FAQs: About Claude Opus 4 and Competitors
Is Claude Opus 4 Free?
No, Claude Opus 4 (4.1 and 4.2) is not free. Anthropic’s paid API, which costs about $75 per million output tokens and is aimed at professional and business users, makes it available. Free trials or limited access may be offered, but full functionality requires a subscription.
What Is the Opus Tool Used For?
Claude Opus 4.1 is designed for advanced AI tasks, including high-level coding, complex reasoning, and agentic workflows. It’s ideal for developers building autonomous agents, researchers handling multi-step problems, and enterprises managing large-scale codebases or data analysis.
Is Opus 4 Better Than Sonnet 4?
It depends on the context. Opus 4.1 surpasses Sonnet 4 in raw intelligence and complex tasks (e.g., higher SWE-bench scores), making it better for intricate, long-form challenges. However, Sonnet 4 is superior in speed, affordability, and everyday efficiency, often preferred for high-volume work.
Is Opus 4 a Reasoning Model?
Yes, Claude Opus 4.1 is a powerful reasoning model. It excels in logical deduction, mathematical problem-solving (90% on high-school math benchmarks), and extended thinking modes, integrating tools for accurate, multi-step outputs.
Is Gemini Better Than Claude?
The answer varies by use case. Google’s Gemini (e.g., 2.5 Pro) often shines in multimodal capabilities, cost-effectiveness, and factual accuracy with larger context windows, making it better for tasks involving images, videos, or real-time data. However, Anthropic’s Claude (especially Opus 4.1) typically outperforms in coding, creative content, and ethical reasoning, with stronger benchmark scores in software engineering. Many users find Claude more reliable for detailed, agentic workflows, while Gemini offers better value for general or budget-conscious applications. Ultimately, test both for your specific needs.
Don’t Miss This : Claude AI Review for Writers, Coders & Creators [2025 Update]
Don’t Miss This : Grok-4 Unleashed: Elon Musk AI Surpasses Real-World Benchmarks and Outperforms GPT-4

