Have you ever wondered how AI could get even smarter? Picture this: an AI that doesn’t just read your text messages but also sees the photo you attached, hears your voice note, and understands the video clip all at once. That’s the magic of multimodal AI, and it’s not some far-off dream—it’s happening right now in 2025. As we dive deeper into this tech, it’s clear that multimodal AI is reshaping how machines interact with the world, making them more intuitive and human-like than ever before.
In simple terms, multimodal AI is like giving machines multiple senses. Instead of being limited to one type of input, like text-only chatbots, these systems process a mix of data—text, images, audio, video, and even more. This blend allows for richer, more accurate responses. For instance, if you’re asking about a recipe, the AI could analyze a photo of your ingredients, listen to your verbal instructions, and pull in text from a cookbook to guide you step by step. It’s a game-changer for everything from everyday apps to complex industries.

But why is this blowing up in 2025? Well, advancements in hardware and algorithms have made it possible to handle massive datasets without lagging. Plus, with more people using smart devices, the demand for seamless, natural interactions is skyrocketing. Let’s break it down further.
How Multimodal AI Works: Combining Senses
At its core, multimodal AI mimics how humans perceive the world—we don’t just hear or see; we combine everything for a full picture. The process starts with gathering data from various sources, like snapping a photo on your phone or recording a voice memo. Then, the AI preprocesses this info to make it usable—cleaning up noisy audio or resizing images.
Next comes feature extraction, where specialized tools pull out key details. For pictures, it might use image recognition to spot objects, colors, or emotions. For text, language models break down words and context. Audio gets analyzed for tone, speech patterns, or background sounds. The real trick is in the fusion stage: the AI merges these features into a unified understanding. This could happen early (blending raw data right away) or late (processing each part separately and combining results at the end).
Think of it like cooking a meal—you gather ingredients (data), chop and prepare them (extraction), and mix them to create something delicious (fusion). Without this integration, you’d have disjointed pieces; with it, you get a cohesive whole that’s way more powerful than single-mode AI.

Unified Models & AI Advances
Gone are the days of clunky, separate AI tools. Today’s unified foundation models, like OpenAI’s GPT-5 or Google’s Gemini, handle multiple inputs in one go. These are built on transformer architectures with clever attention mechanisms that link, say, a visual detail in an image to a descriptive word in text. This setup lets AI “see and speak”—recognizing faces in photos, picking up on sarcasm in voice, or even gauging emotions from audio cues.
In 2025, these models are getting even better at cross-modal reasoning. For example, GPT-5 can take a video input, understand the scene, and generate code or text based on it. Gemini shines in coding and multimodal tasks, processing code alongside images or audio for more creative outputs. Advances in neural networks mean faster processing and fewer errors, paving the way for AI that’s not just smart but context-aware.
On-Device and Edge AI
One of the biggest shifts in 2025 is AI moving from distant cloud servers to your pocket. Smartphones, laptops, and even wearables now run multimodal models locally, thanks to powerful chips like Apple’s Neural Engine or Qualcomm’s AI accelerators. This “on-device” approach means instant responses—no waiting for data to ping a server.
The perks? Better privacy, since your photos or voice stays on your device. Reliability in spotty internet zones, like remote areas or during travel. And in sensitive fields like healthcare, it’s a must for quick, secure decisions. Imagine a doctor’s tablet analyzing an X-ray image and patient notes in real-time, without risking data leaks. Edge AI takes it further, processing at the “edge” of networks for ultra-low latency in things like self-driving cars or smart factories.
Related Stories
Artificial Intelligence: Everything You Need to Know – Types, Uses & Future
What Is Agentic AI? The Rise of Autonomous AI Agents in 2025
Real-World Use Cases
Multimodal AI isn’t just theory—it’s out there solving problems. In healthcare, systems like IBM Watson Health combine MRI scans, patient records, and voice notes from doctors to spot diseases earlier and more accurately. This could mean faster diagnoses for conditions like cancer, where every detail counts.
Customer service is another winner. Chatbots now handle screenshots from users, email threads, and call audio to resolve issues quicker. No more repeating yourself— the AI gets the full context.
On consumer devices, AI copilots like those in Windows PCs or Android phones use your camera, mic, and texts together. Shopping? Snap a pic of an outfit, describe what you want in voice, and get tailored suggestions. Planning a trip? It scans your photos, listens to preferences, and reads reviews to build an itinerary.
Other cool examples: In education, apps analyze video lectures with subtitles and images for interactive learning. In entertainment, tools like Runway or Sora generate videos from text prompts mixed with audio clips.
Business Impact & Benefits
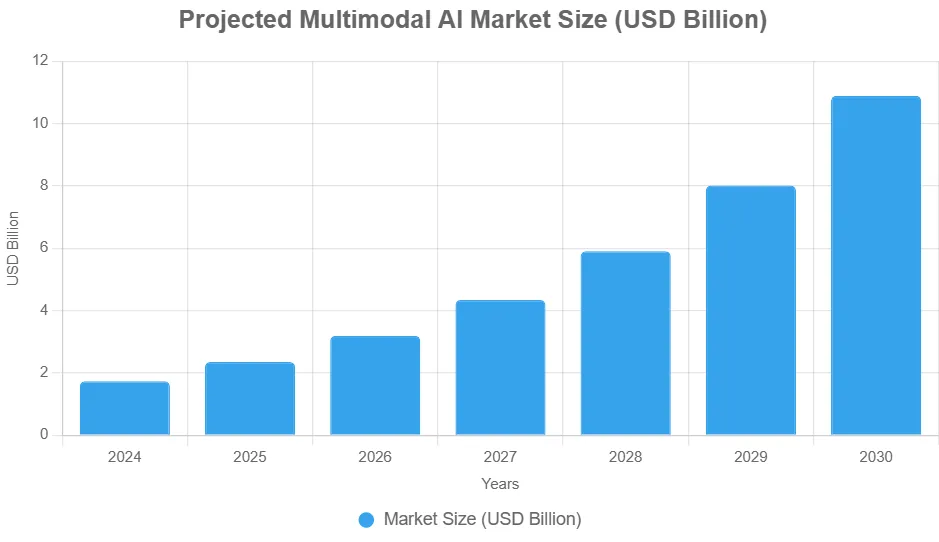
The business world is all in on this. The global multimodal AI market was worth about USD 1.73 billion in 2024 and is projected to hit USD 10.89 billion by 2030, growing at a compound annual growth rate (CAGR) of 36.8%. That’s huge, driven by investments in smarter interfaces and efficiency boosts.
Benefits? Enhanced user experiences through intuitive apps, like AR shopping where AI overlays products on your camera feed while chatting with you. Productivity soars—78% of organizations used AI in 2024, up from 55% in 2023, and multimodal tech is a big part of that adoption. Industries from retail to finance are seeing innovation spikes, with AI handling complex tasks that once needed human oversight.
To visualize the growth, here’s a suggested bar chart:
Challenges & Considerations
Of course, it’s not all smooth sailing. Training these models demands massive datasets and heavy-duty hardware, like GPUs, which can rack up costs and energy use. Integrating data types is tricky—mismatches in timing or format can lead to errors.
Privacy is a hot button. With richer data comes bigger risks; think encryption and ethical guidelines to protect users. Bias is another issue—diverse training data is key to avoid skewed results. Developers are tackling this with better standards and audits.
Future Outlook (2025 and Beyond)
Looking ahead, multimodal AI will evolve into true smart assistants. By 2025 and into the 2030s, expect AI that anticipates needs across senses—watching your surroundings, listening to conversations, and advising seamlessly.
Immersive tech like AR/VR will thrive, with AI reacting to what you see and say in virtual worlds for training or gaming. Hybrid setups—edge for quick tasks, cloud for heavy lifting—will balance speed and power. Trends include smaller, customizable models and ethical AI focus.

In wrapping up, multimodal AI is the bridge to intelligent machines that truly understand us. As we navigate its growth, balancing innovation with responsibility will be key. Whether you’re a tech enthusiast or business leader, this is the future unfolding—get ready to embrace it.
FAQs
What is multimodal AI?
Multimodal AI is a type of artificial intelligence that processes and integrates multiple types of data, such as text, images, audio, and video, to provide more comprehensive and accurate outputs. It mimics human sensory integration for better understanding.
What is the future of multimodal AI?
The future involves more immersive, context-aware assistants, widespread AR/VR integration, and hybrid edge-cloud systems. By 2030, it could transform industries with smarter, ethical AI.
How to create multimodal AI?
Start with collecting diverse datasets, use frameworks like TensorFlow or PyTorch for feature extraction and fusion, train on powerful hardware, and fine-tune with techniques like transfer learning. Tools like Hugging Face libraries can help.
What is the main advantage of multimodal AI?
Its ability to combine multiple data types for richer context, leading to higher accuracy, fewer errors, and more natural interactions compared to single-mode AI.
What is the difference between generative AI and multimodal AI?
Generative AI creates new content like text or images from prompts, often unimodal. Multimodal AI extends this by handling multiple input/output types for more complex, integrated tasks.
What is an example of a multimodal model?
Google’s Gemini, which processes text, images, audio, code, and video to generate responses, code, or analyses.

